

搜索到
12
篇与
的结果
-
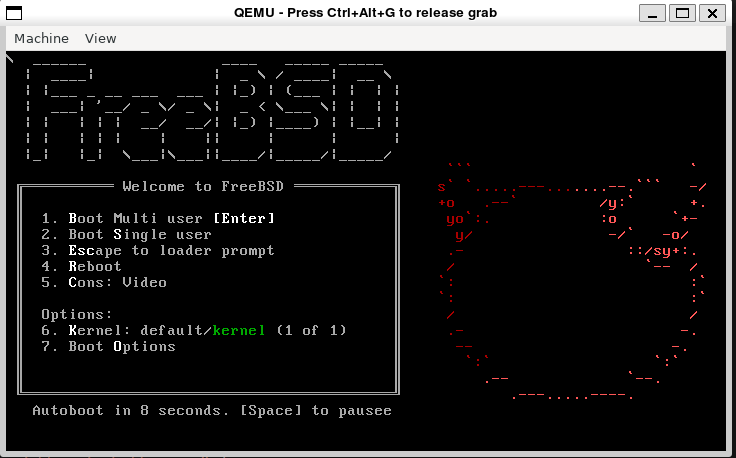
 FreeBSD Kernel-编译环境搭建 FreeBSD Kernel-编译环境搭建0 概述本文章介绍一个搭建基于Qemu的FreeBSD虚拟机、在Linux下交叉编译FreeBSD内核并替换FreeBSD内核的开发环境。1 文件准备我把以下的步骤都打包为一个docker image:yirannn/modular-os-env,如果你使用该镜像,可以略过文件准备部分1.1 FreeBSD SRC你可以在官方网站或者科大镜像下载你需要的文件,其中src.txz为FreeBSD的源码1.2 FreeBSD QCOW2你可以在官方网站或者科大镜像下载qemu可用的qcow2文件,用于作为替换内核的基础镜像1.3 编译软件包下载好文件后,你可以选择参照我的镜像Dockerfile来安装软件包。apt-get install qemu-system wget bmake gcc g++ clang-14 lld-14 libarchive-dev1.4 启动Dockerdocker run -it --name modular-os-zswap --privileged=true yirannn/modular-os-env bash如果出现 mount无权限、qemu无kvm,首先怀疑是不是privileged没打开2 编译2.1 编译命令的来源FreeBSD的源码并未直接准备好在Linux下编译,但是在FreeBSD 13之后,官方开始在macOS、Linux下进行交叉编译,并提供了Github CI进行验证。我在Action中翻到了相关的编译命令,仿照相关命令进行编译。这意味着我其实并不知道每一步具体都干了什么,如果你对此有疑问,建议可以自行查阅FreeBSD的Github Actionname: Cross-build Kernel on: push: branches: [ main, 'stable/13' ] pull_request: branches: [ main ] permissions: contents: read jobs: build: name: ${{ matrix.target_arch }} ${{ matrix.os }} (${{ matrix.compiler }}) runs-on: ${{ matrix.os }} strategy: fail-fast: false matrix: target_arch: [ amd64, aarch64 ] os: [ ubuntu-20.04, ubuntu-22.04, macos-latest ] include: # TODO: both Ubuntu and macOS have bmake packages, we should try them instead of bootstrapping our own copy. - os: ubuntu-20.04 compiler: clang-12 cross-bindir: /usr/lib/llvm-12/bin pkgs: bmake libarchive-dev clang-12 lld-12 - os: ubuntu-22.04 compiler: clang-14 cross-bindir: /usr/lib/llvm-14/bin pkgs: bmake libarchive-dev clang-14 lld-14 - os: macos-latest compiler: clang-13 cross-bindir: /usr/local/opt/llvm@13/bin pkgs: bmake libarchive llvm@13 - target_arch: amd64 target: amd64 - target_arch: aarch64 target: arm64 steps: - uses: actions/checkout@v3 - name: install packages (Ubuntu) if: runner.os == 'Linux' run: | sudo apt-get update --quiet || true sudo apt-get -yq --no-install-suggests --no-install-recommends install ${{ matrix.pkgs }} - name: install packages (macOS) if: runner.os == 'macOS' run: | brew update --quiet || true brew install ${{ matrix.pkgs }} || true - name: create environment run: | echo "GITHUB_WORKSPACE = $GITHUB_WORKSPACE" if [ -n "${{ matrix.cross-bindir }}" ]; then echo "EXTRA_BUILD_ARGS=--cross-bindir=${{ matrix.cross-bindir }}" >> $GITHUB_ENV fi mkdir -p ../build echo "MAKEOBJDIRPREFIX=${PWD%/*}/build" >> $GITHUB_ENV # heh, works on Linux/BSD/macOS ... echo "NPROC=`getconf _NPROCESSORS_ONLN 2>/dev/null || getconf NPROCESSORS_ONLN 2>/dev/null || echo 1`" >> $GITHUB_ENV - name: bootstrap bmake run: ./tools/build/make.py --debug $EXTRA_BUILD_ARGS TARGET=${{ matrix.target }} TARGET_ARCH=${{ matrix.target_arch }} -n - name: make kernel-toolchain run: ./tools/build/make.py --debug $EXTRA_BUILD_ARGS TARGET=${{ matrix.target }} TARGET_ARCH=${{ matrix.target_arch }} kernel-toolchain -s -j$NPROC -DWITH_DISK_IMAGE_TOOLS_BOOTSTRAP - name: make buildkernel run: ./tools/build/make.py --debug $EXTRA_BUILD_ARGS TARGET=${{ matrix.target }} TARGET_ARCH=${{ matrix.target_arch }} KERNCONF=GENERIC NO_MODULES=yes buildkernel -s -j$NPROC $EXTRA_MAKE_ARGS2.2 编译FreeBSD的编译需要几个环境变量,我们构建如下的目录结构parent --|-- src | |--- tools --- build | |-- obj并在parent目录下声明如下变量export BASEDIR=$(pwd) export MAKEOBJDIRPREFIX=$BASEDIR/obj这之后,进入src目录,开始编译cd $BASEDIR/src # 进入src目录 ./tools/build/make.py --debug --cross-bindir=/usr/lib/llvm-14/bin/ TARGET=amd64 TARGET_ARCH=amd64 -n # Bootstrap ./tools/build/make.py --debug --cross-bindir=/usr/lib/llvm-14/bin/ TARGET=amd64 TARGET_ARCH=amd64 kernel-toolchain -s -j32 -DWITH_DISK_IMAGE_TOOLS_BOOTSTRAP # Toolchain ./tools/build/make.py --debug --cross-bindir=/usr/lib/llvm-14/bin/ TARGET=amd64 TARGET_ARCH=amd64 KERNCONF=GENERIC NO_MODULES=yes buildkernel -s -j32 # Kernel其中 cross-bindir 指示了用于交叉编译的编译器二进制文件存放目录,TARGET和TARGET_ARCH指示了交叉编译的目标系统架构,编译好的内核在 obj/root/source/freebsd/src/amd64.amd64/sys/GENERIC/kernel.full3 内核替换3.1 准备共享区共享区是为了把宿主机编译好的 kernel.full 传递给 qemu 启动的虚拟机首先创建一块4M*1K的虚拟磁盘,用ext4格式化dd if=/dev/zero of=/opt/share.img bs=4M count=1k mkfs.ext4 /opt/share.img创建一个目录,把该虚拟磁盘文件挂到该目录,并把编译好的内核放在该目录中如果 mount 无权限,但已经在超级用户权限下了,考虑是否容器启动没有priviledgedmkdir /tmp/share mount -o loop /opt/share.img /tmp/share cp $BASEDIR/obj/root/source/freebsd/src/amd64.amd64/sys/GENERIC/kernel.full /tmp/share3.2 准备虚拟机3.2.1 启动虚拟机在第一步骤中已经下载好了qcow2在本步骤中我们进行一个使用unxz FreeBSD-12.4-RELEASE-amd64.qcow2.xz qemu-img resize FreeBSD-12.4-RELEASE-amd64.qcow2 +1G # 调整镜像大小,如果不调整,后续无法安装软件包这之后,使用qemu启动FreeBSDqemu-system-x86_64 -drive file=FreeBSD-12.4-RELEASE-amd64.qcow2,format=qcow2 -enable-kvm -hdb /opt/share.img目前qemu启动FreeBSD还必须用一个图形界面,如果使用-nographic 选项,会导致FreeBSD无法正常Boot这之后,使用root用户登录,没有密码输入uname -a 查看内核版本,可以看到我们加载的是 FreeBSD 12.4接下来挂载我们刚刚准备好的共享区pkg install sysutils/fusefs-ext2这一步需要按两次y,并有可能出现磁盘空间不足的问题。这可能是由于前步未执行扩展qcow2指令导致的3.2.2 如果空间不足怎么办关闭虚拟机,回到宿主机,尝试扩展qcow2文件qemu-img resize FreeBSD-12.4-RELEASE-amd64.qcow2 +1G重新用刚刚的命令启动qemu,在FreeBSD中gpart show可以看到freebsd-ufs的空间情况和分区号使用gpart扩展ufs分区gpart resize -i 4 -a 4k -s 5G ada0 growfs /dev/gpt/rootfs重新安装fusefs-ext2模块3.2.3 挂载使用camcontrol命令查看当前系统的硬件设备第一块盘ada0是启动的系统盘,第二块是我们在qemu中用hdb参数挂上去的共享盘用fuse-ext2对这个盘进行映射kldload fuse.ko # 如果不注册,每次用都得加载一下 mkdir /share fuse-ext2 /dev/ada1 /share ls /share把kernel替换掉cd /boot/kernel mv kernel kernel.old cp /share/kernel.full ./kernel reboot等待系统重启,重新uname -a此时可以看到内核已经更新到我们编译的13.2
FreeBSD Kernel-编译环境搭建 FreeBSD Kernel-编译环境搭建0 概述本文章介绍一个搭建基于Qemu的FreeBSD虚拟机、在Linux下交叉编译FreeBSD内核并替换FreeBSD内核的开发环境。1 文件准备我把以下的步骤都打包为一个docker image:yirannn/modular-os-env,如果你使用该镜像,可以略过文件准备部分1.1 FreeBSD SRC你可以在官方网站或者科大镜像下载你需要的文件,其中src.txz为FreeBSD的源码1.2 FreeBSD QCOW2你可以在官方网站或者科大镜像下载qemu可用的qcow2文件,用于作为替换内核的基础镜像1.3 编译软件包下载好文件后,你可以选择参照我的镜像Dockerfile来安装软件包。apt-get install qemu-system wget bmake gcc g++ clang-14 lld-14 libarchive-dev1.4 启动Dockerdocker run -it --name modular-os-zswap --privileged=true yirannn/modular-os-env bash如果出现 mount无权限、qemu无kvm,首先怀疑是不是privileged没打开2 编译2.1 编译命令的来源FreeBSD的源码并未直接准备好在Linux下编译,但是在FreeBSD 13之后,官方开始在macOS、Linux下进行交叉编译,并提供了Github CI进行验证。我在Action中翻到了相关的编译命令,仿照相关命令进行编译。这意味着我其实并不知道每一步具体都干了什么,如果你对此有疑问,建议可以自行查阅FreeBSD的Github Actionname: Cross-build Kernel on: push: branches: [ main, 'stable/13' ] pull_request: branches: [ main ] permissions: contents: read jobs: build: name: ${{ matrix.target_arch }} ${{ matrix.os }} (${{ matrix.compiler }}) runs-on: ${{ matrix.os }} strategy: fail-fast: false matrix: target_arch: [ amd64, aarch64 ] os: [ ubuntu-20.04, ubuntu-22.04, macos-latest ] include: # TODO: both Ubuntu and macOS have bmake packages, we should try them instead of bootstrapping our own copy. - os: ubuntu-20.04 compiler: clang-12 cross-bindir: /usr/lib/llvm-12/bin pkgs: bmake libarchive-dev clang-12 lld-12 - os: ubuntu-22.04 compiler: clang-14 cross-bindir: /usr/lib/llvm-14/bin pkgs: bmake libarchive-dev clang-14 lld-14 - os: macos-latest compiler: clang-13 cross-bindir: /usr/local/opt/llvm@13/bin pkgs: bmake libarchive llvm@13 - target_arch: amd64 target: amd64 - target_arch: aarch64 target: arm64 steps: - uses: actions/checkout@v3 - name: install packages (Ubuntu) if: runner.os == 'Linux' run: | sudo apt-get update --quiet || true sudo apt-get -yq --no-install-suggests --no-install-recommends install ${{ matrix.pkgs }} - name: install packages (macOS) if: runner.os == 'macOS' run: | brew update --quiet || true brew install ${{ matrix.pkgs }} || true - name: create environment run: | echo "GITHUB_WORKSPACE = $GITHUB_WORKSPACE" if [ -n "${{ matrix.cross-bindir }}" ]; then echo "EXTRA_BUILD_ARGS=--cross-bindir=${{ matrix.cross-bindir }}" >> $GITHUB_ENV fi mkdir -p ../build echo "MAKEOBJDIRPREFIX=${PWD%/*}/build" >> $GITHUB_ENV # heh, works on Linux/BSD/macOS ... echo "NPROC=`getconf _NPROCESSORS_ONLN 2>/dev/null || getconf NPROCESSORS_ONLN 2>/dev/null || echo 1`" >> $GITHUB_ENV - name: bootstrap bmake run: ./tools/build/make.py --debug $EXTRA_BUILD_ARGS TARGET=${{ matrix.target }} TARGET_ARCH=${{ matrix.target_arch }} -n - name: make kernel-toolchain run: ./tools/build/make.py --debug $EXTRA_BUILD_ARGS TARGET=${{ matrix.target }} TARGET_ARCH=${{ matrix.target_arch }} kernel-toolchain -s -j$NPROC -DWITH_DISK_IMAGE_TOOLS_BOOTSTRAP - name: make buildkernel run: ./tools/build/make.py --debug $EXTRA_BUILD_ARGS TARGET=${{ matrix.target }} TARGET_ARCH=${{ matrix.target_arch }} KERNCONF=GENERIC NO_MODULES=yes buildkernel -s -j$NPROC $EXTRA_MAKE_ARGS2.2 编译FreeBSD的编译需要几个环境变量,我们构建如下的目录结构parent --|-- src | |--- tools --- build | |-- obj并在parent目录下声明如下变量export BASEDIR=$(pwd) export MAKEOBJDIRPREFIX=$BASEDIR/obj这之后,进入src目录,开始编译cd $BASEDIR/src # 进入src目录 ./tools/build/make.py --debug --cross-bindir=/usr/lib/llvm-14/bin/ TARGET=amd64 TARGET_ARCH=amd64 -n # Bootstrap ./tools/build/make.py --debug --cross-bindir=/usr/lib/llvm-14/bin/ TARGET=amd64 TARGET_ARCH=amd64 kernel-toolchain -s -j32 -DWITH_DISK_IMAGE_TOOLS_BOOTSTRAP # Toolchain ./tools/build/make.py --debug --cross-bindir=/usr/lib/llvm-14/bin/ TARGET=amd64 TARGET_ARCH=amd64 KERNCONF=GENERIC NO_MODULES=yes buildkernel -s -j32 # Kernel其中 cross-bindir 指示了用于交叉编译的编译器二进制文件存放目录,TARGET和TARGET_ARCH指示了交叉编译的目标系统架构,编译好的内核在 obj/root/source/freebsd/src/amd64.amd64/sys/GENERIC/kernel.full3 内核替换3.1 准备共享区共享区是为了把宿主机编译好的 kernel.full 传递给 qemu 启动的虚拟机首先创建一块4M*1K的虚拟磁盘,用ext4格式化dd if=/dev/zero of=/opt/share.img bs=4M count=1k mkfs.ext4 /opt/share.img创建一个目录,把该虚拟磁盘文件挂到该目录,并把编译好的内核放在该目录中如果 mount 无权限,但已经在超级用户权限下了,考虑是否容器启动没有priviledgedmkdir /tmp/share mount -o loop /opt/share.img /tmp/share cp $BASEDIR/obj/root/source/freebsd/src/amd64.amd64/sys/GENERIC/kernel.full /tmp/share3.2 准备虚拟机3.2.1 启动虚拟机在第一步骤中已经下载好了qcow2在本步骤中我们进行一个使用unxz FreeBSD-12.4-RELEASE-amd64.qcow2.xz qemu-img resize FreeBSD-12.4-RELEASE-amd64.qcow2 +1G # 调整镜像大小,如果不调整,后续无法安装软件包这之后,使用qemu启动FreeBSDqemu-system-x86_64 -drive file=FreeBSD-12.4-RELEASE-amd64.qcow2,format=qcow2 -enable-kvm -hdb /opt/share.img目前qemu启动FreeBSD还必须用一个图形界面,如果使用-nographic 选项,会导致FreeBSD无法正常Boot这之后,使用root用户登录,没有密码输入uname -a 查看内核版本,可以看到我们加载的是 FreeBSD 12.4接下来挂载我们刚刚准备好的共享区pkg install sysutils/fusefs-ext2这一步需要按两次y,并有可能出现磁盘空间不足的问题。这可能是由于前步未执行扩展qcow2指令导致的3.2.2 如果空间不足怎么办关闭虚拟机,回到宿主机,尝试扩展qcow2文件qemu-img resize FreeBSD-12.4-RELEASE-amd64.qcow2 +1G重新用刚刚的命令启动qemu,在FreeBSD中gpart show可以看到freebsd-ufs的空间情况和分区号使用gpart扩展ufs分区gpart resize -i 4 -a 4k -s 5G ada0 growfs /dev/gpt/rootfs重新安装fusefs-ext2模块3.2.3 挂载使用camcontrol命令查看当前系统的硬件设备第一块盘ada0是启动的系统盘,第二块是我们在qemu中用hdb参数挂上去的共享盘用fuse-ext2对这个盘进行映射kldload fuse.ko # 如果不注册,每次用都得加载一下 mkdir /share fuse-ext2 /dev/ada1 /share ls /share把kernel替换掉cd /boot/kernel mv kernel kernel.old cp /share/kernel.full ./kernel reboot等待系统重启,重新uname -a此时可以看到内核已经更新到我们编译的13.2 -
Linux Kernel-THP阅读分析[Hang up] THP阅读分析[WIP]本文由于工作优先级原因暂时搁置,专心转向zswap// TODO[x] 配置源码阅读环境 第三部分-Linux源码阅读环境[ ] 理清如下几个先决问题[x] 什么是THP?THP要做什么?[ ] 为什么在虚拟化和嵌套页表的情况下,THP对TLB和TLB miss的优化更明显[x] THP和HP的相关性与区别[ ] THP和HugeTLB的相关性与区别[ ] 梳理THP相关核心流程[x] khugepaged守护进程如何工作?[x] khugepaged与huge_memory关系如何?[ ] huge_memory如何管理大页面,更一般的,理清下面两个问题[ ] 一次内存访问中发生了什么[ ] 一次页错误中发生了什么[ ] 梳理THP相关核心数据结构[ ] 理清如下几个逻辑问题[ ] 一个mm是管理一个进程内存空间的数据结构?核心代码:huge_memory.ckhugepaged.c官方文档:Transparent Hugepage Support概述 (暂时性的,不一定正确)Hugepage:现代操作系统使用的页式内存管理通常以4K为一个标准页面。在内存越来越大的今天,4K大小的页面对于使用大量内存的应用会产生一些问题,即大量产生的缺页中断。大量的缺页中断会带来两个问题 1. 进入内核的次数更多,带来更多的切换上下文开销。 2. 带来更多的TLB Miss,这也是Hugepage优化的主要问题。 对于问题a,大页带来的性能优化可能较低。一方面更大的页面要求在一次页错误中复制更多的内容。另一方面,进出内核的频率降低只在内存映射的生命周期内第一次访存时才重要。对于问题b,因为TLB的容量是有限的,更大的页面也代表着更少的页面,这会带来两点好处 1. TLB miss会变快 2. 一个TLB表项可以映射更大的内存,来减少TLB miss THP:THP和Hugepage的区别是:Hugepage是一个操作系统管理的、用户显式请求的机制,THP是操作系统自动的,对用户透明的行为。THP无需用户修改代码,具有更高的普适性。khugepaged负责合并,huge_memory.c中的函数负责管理透过现象看本质,这是一种用单页面大小和扫描时间换系统整体效率的机制部分概念/缩写介绍[WIP]页表条目现在的Linux内核采用四级页表目录的方式,分别为PGD :Page Global DirectoryPUD :Page Upper DirectoryPMD :Page Middle DirectoryPTE :Page Table Entry来复习下基础:每个进程都有自己独立的PGD,虚拟地址的从高到底的k位(典型的是9,最低12位是页框内地址,共48位的地址)分别用来索引PGD(在PGD中找到这个地址对应的PUD)、索引PUD、索引PMD、索引PTE进而找到自己对应的物理页框,最低几位在该页框中索引具体的内存地址。PUD、PMD和PTE的最低位是存储是否有效的标志位。其中PTE指示页框的是48...12这36位。THP运转流程-合并概述在系统启动时,内核会启动khugepaged守护进程,该进程启动一个核心循环,扫描系统中的页面,检测是否有多个连续的页面可以合并为一个透明大页(事实上,我认为不是任意连续2M页面,而必须是已经存在的PMD表项所对应的2M页面,待确认)。当它发现了可以合并的页面后进行大量的检查操作,然后进入合并函数。先进行申请和double-check,移除CPU中的TLB对应表项,复制巨页内容,更新相关参数。khugepaged如何初始化在hugememory.c中,有一个被subsys_initcall注册的初始化函数:hugepage_init, 该函数调用了两个khugepaged相关的函数:khugepaged_init 和 start_stop_khugepaged,在此处,我们暂时先不关心其他的初始化流程,把它们放到管理中去考虑,先只看khugepaged相关的部分khugepaged_init申请一段slab内存,初始化四个参数常量 HPAGE_PMD_NR 根据它的定义,我推测它在数量上和一个HPAGE所含的一般页面数量相等(512)khugepaged_pages_to_scan : 每次扫描页面的数量,默认为 512 * 8khugepaged_max_ptes_none:最多有多少个页表项是空页面(存疑)khugepaged_max_ptes_swap:最多有多少个页面在swap中未被映射,默认是512/8khugepaged_max_ptes_shared:最多有多少页面是被共享的,默认是512/2start_stop_khugepaged获取互斥锁,检测hugepage是否开启了,若开启了则检查static变量khugepaged_thread,存在则关闭该线程启动一个内核线程,目标函数为khugepaged函数,该函数为khugepaged扫描的核心循环若有错误,清理并释放锁khugepaged如何扫描khugepaged设置一些状态,把当前线程优先级变低,进入循环如果收到KTHREAD_SHOULD_STOP,则退出调用khugepaged_do_scan函数调用khugepaged_wait_work函数,进入等待根据khugepaged_scan_sleep_millisecs,转换成中断次数,进入等待获取自旋锁,进行一些清理工作,释放锁khugepaged_do_scan该函数有一个参数:khugepaged_collapse_control,只透传给下层初始化一些变量progress:记录THP扫描进度pages:读取init中初始化的khugepaged_pages_to_scanwait:布尔量,用于下面过程的重试result:记录扫描结果的状态调用lru_add_drain_all函数,把脏页从LRU列表干掉(加到写回缓冲区)进入一个无限循环,降低自己的优先级检查是否要退出获取一个自旋锁如果当前kugepaged_scan的mm_slot字段为空,累加“pass_through_head”计数器如果kugepaged_scan的mm_head不为空,且pass_through_head < 2(我理解就是第一次进入,记录一个TODO,为什么要把0的情况算进去,即什么情况下存在刚进入do_scan函数但是mm_slot不为空)调用kugepaged_scan_mm_slot函数,并把结果累加给progress变量,更新result变量kugepaged_scan_mm_slotstatic unsigned int khugepaged_scan_mm_slot(unsigned int pages, int *result, struct collapse_control *cc) __releases(&khugepaged_mm_lock) __acquires(&khugepaged_mm_lock)该函数是scan步骤的关键函数,它接受的参数包括:pages:要扫描的页数result:结果指针cc:透传来的 collapse_control结构该函数首先进行一些初始化与验证操作,包括对参数与锁的断言,对 result 的初始化检测是否已经有正在进行的扫描,如果有,获取相应的 mm_slot和 slot(扫描当前头部未扫描完的进程),如果没有,初始化一组新的 slot 和 mm_slot(扫描下一个进程)khugepaged如何合并kugepaged_collapse_pte_mapped_thps进行一些验证操作与锁的获取便利当前 slot 的所有 Hugepage 的页表项,调用collapse_pte_mapped_thp函数对这些页表项进行合并操作。collapse_pte_mapped_thpint collapse_pte_mapped_thp(struct mm_struct *mm, unsigned long addr, bool install_pmd)该函数有三个参数● mm:将要被聚合的进程地址空间● addr:要发生聚合的地址● install_pmd:布尔,决定是否应当设置一个 PMD 表项该函数检测是否一个 PMD 中的所有 PTE 表项都指向了正确的 THP,如果是的话,撤销相关的页表项,这样 THP 可以触发一个新的页错误,使得使用一个 huge PMD 映射这个 THP把地址按掩码对齐,获取当前地址对应的 vma,获取锁。调用find_pmd_or_thp_or_none 查找页表中对应当前地址的 PMD 或是 THP 或是空指针。如果当前页面已经被 PMD 映射,返回。如果所有检测都没有命中,返回 SCAN_SUCCEED。// TODO:这些检测都是什么检查获取的 vma 是否正确,如果不正确,返回 VMA_CHECK,表示需要检查虚拟内存区域到此为止,我门已经成功的把页缓存中的本地页面替换成了单个的 hugepage,如果 mm 触发缺页错误,当前 hugepage 就会被一个 PMD 映射,而不考虑 sysfs 中对 THP 的设置是什么样的。检查是否存在使用 userfaultfd_wp的情况,如果是,返回通过 find_lock_page 尝试获取页面,且验证页面是一个 Hugepage,并且检测页面是否为一个复合页面。如果不是 Hugepage 或者页面复合阶数和 HPAGE_PMD_ORDER不相等,则 drop_hpage。接下来操作页表,首先获取当前 vma 的锁、当前文件映射的锁、当前虚拟地址对应 PTE 的锁。STEP1:检测是否所有的已映射页表项指向了期望的 Hugepage● 遍历当前 PMD 对应的所有 PTE● 如果当前 PTE 是空,跳过● 如果当前 PTE 没有物理页映射,发生了非法情况,终止(swapped out)● 获取 PTE 指向的物理页面 ● 检测是否是设备内存,如果是,WARN,并设置页面指针为 NULL● 检测 PTE 指向的页面和期望的巨页对应的小页面是否一致,不一致则终止● 累加计数器STEP2:对小页面的反向映射进行调整● 遍历当前 HugePage 的页表项● 如果当前 PTE 是空的,跳过● 获取当前物理页,检测是否是设备内存,若是 WARN 并 abort● 调用 page_remove_rmap,从页的反向映射表中移除页面与 VMA 的映射关系● 解锁 PTE 的映射STEP3、4:设置正确的引用计数、移除 PTE 条目● 如果 count 不是 0,说明签名的步骤中找到了一些映射到 hpage 的 PTE 条目,折叠后会删除 PTE,所以更新 hpage 的引用计数、把 vma 的 mm 计数器也减掉相应的数量● 如果有匿名 vma,获取锁,然后调用 collapse_and_free_pmd折叠并释放 haddr 处的 PMD 条目STEP5:● 根据 install_pmd 参数的情况,决定是否要安装 PMD,若 PMD 安装成功或者不需要,则返回 SCAN_SUCCEEDcollapse_and_free_pmdhugepage_vma_checkkhugepaged的重要数据结构khugepagd_scanstruct khugepaged_scan { struct list_head mm_head; struct khugepaged_mm_slot *mm_slot; unsigned long address; }; 这个数据结构是一个指引扫描的“光标”,跟踪khugepaged扫描时的状态。该数据结构只会有一个全局实例。mm_head:要扫描的mm的头部,维护需要扫描内存区的链表mm_slot:指向当前正在扫描的kuhugepaged_mm_slotaddress:是mm_slot内下一个即将被扫描的地址khugepaged_mm_slotstruct khugepaged_mm_slot { struct mm_slot slot; /* pte-mapped THP in this mm */ int nr_pte_mapped_thp; unsigned long pte_mapped_thp[MAX_PTE_MAPPED_THP]; };这个数据结构用来跟踪正在扫描的每个内存区域slot:依赖的一个外部数据结构,实现了从mm到mm_slot的哈希查找nr_pte_mapped_thp:表示在该mm中已经被映射的THP的数量pte_mapped_thp:存放该mm中已映射的THP的地址在我的理解中,khugepaged_scan指导scan工作,而其中的mm_slot指向当前正在被扫描的那个进程的mm_slot,(一个进程通常只有一个kugepaged_mm_slot, 暂不确定什么情况下会有多个)THP运转流程-管理
-
Linux Kernel-源码阅读环境搭建 Linux源码阅读环境这里主要使用Vscode+Clangd的方式。使用我们之前的docker启动一个环境docker run -it --name src_reading --privileged=true -p2233:22 yirannn/modular-zswap-env bash先处理docker端提示环境安装clangd,由于clangd和编译过程联系紧密,所以我们选择不在windows上而直接在remote上放代码。安装bear,它辅助我们创建Compilation Database, 它会记录每个c文件的依赖和编译选项apt-get install clangd bear编译在对应的目录下,运行make clean bear -- make即可通过一次编译生成Compilation Database再处理前端安装一个Vscode-Docker插件(Container-dev亦可)attach一个vscode上去在远程安装一个clangd后端这之后打开文件,clangd 就会提供补全、引用相关的功能了。FAQ在我给 ARM 机器安装 clangd 环境的时候,出现了 Clangd Request Error : Invalid AST 的问题需要在项目根目录下创建.clangd配置文件,在 CompileFlags 下添加一行 Remove,参见https://github.com/clangd/clangd/issues/1582CompileFlags: Remove: [-march=*, -mabi=*]
-
Linux Kernel-编译调试环境搭建 编译环境搭建结束CTF的旅程之后,要投身Kernel的开发。除了日常会偶尔用到的一些脚本环境需要安装在本机之外,我决定所有的环境都打包成Docker使用,避免环境爆炸。目前来看,我暂时主要需要两个环境,一个是学习Rust的环境,该环境有一个Rust和Windows下的Clion即可。另一个是一个可以编译、模拟Unix内核的环境,该环境需要支持FreeBSD和Linux内核的编译,并使用Qemu可以模拟执行、使用GDB调试这些内核的环境Sys编译调试环境2.1 环境准备首先编写Dockerfile,使用Ubuntu22.04 作为基础镜像,换了下apt源,安装一些工具,然后拷贝了linux6.4和freebsd13.2并解压,还准备了一份busybox。当然,你也可以选择用我push好的镜像。docker pull yirannn/modular-zswap-envFROM ubuntu:22.04 RUN sed -ri.bak -e 's/\/\/.*?(archive.ubuntu.com|mirrors.*?)\/ubuntu/\/\/mirrors.pku.edu.cn\/ubuntu/g' -e '/security.ubuntu.com\/ubuntu/d' /etc/apt/sources.list RUN apt-get update && \ apt-get install -y \ # 常用环境和工具 qemu-system make gcc g++ gdb \ git xz-utils bzip2 wget file\ # 用于编译过程 flex bison \ build-essential libncurses-dev \ libelf-dev bc libssl-dev \ # 用于源码阅读 clangd bear RUN mkdir /root/source && \ mkdir /root/tools COPY linux-6.4.tar.gz /root/source COPY freebsd-13.2.tar.txz /root/source COPY busybox-1.36.1.tar.bz2 /root/tools # 其实拷贝压缩包多了个 overlay, 但是影响很小,放在这还方便改 RUN tar xzf /root/source/linux-6.4.tar.gz -C /root/source/ && \ tar xJf /root/source/freebsd-13.2.tar.txz -C /root/source/ && \ tar xjf /root/tools/busybox-1.36.1.tar.bz2 -C /root/tools && \ rm /root/source/linux-6.4.tar.gz /root/source/freebsd-13.2.tar.txz /root/tools/busybox-1.36.1.tar.bz2 && \ mv /root/source/usr /root/source/freebsd WORKDIR /root/source这之后,编译镜像并启动docker build -t $image_name . docker run -it --name $container_name --privileged=true $image_name bash2.2 Linux内核2.2.1 编译选项逐行执行以下命令cd linux-6.4 export ARCH=x86 make x86_64_defconfig make menuconfig在menuconfig中,开启debuginfo、关闭地址随机化。也可以看一看其他的选项Kernel hacking ---> [*] Kernel debugging Compile-time checks and compiler options ---> [*] Provide GDB scripts for kernel debugging Debug infomation ([Disable debug infomation]) ---> (X) Generate DWARF Version 5 debuginfo Processor type and features ----> [] Randomize the address of the kernel image (KASLR)2.2.2 开始编译这之后开始编译,我的笔记本8c16t,设置并发数为16了make -j16 ls /root/source/linux-6.4/arch/x86/boot > bzImage2.3 准备文件系统2.3.1 准备busybox启动内核还需要一个具有根文件系统的磁盘镜像文件,根文件系统中提供可供交互的shell程序以及一些常用工具命令,我们借助busybox工具来制作根文件系统。cd /root/tools/busybox-1.36.1 make menuconfig在config中设置为静态编译Settings ---> [*] Build BusyBox as a static binary (no shared libs)2.3.2 准备rootfs创建一个文件,并格式化为ext4dd if=/dev/zero of=rootfs.img bs=1M count=10 mkfs.ext4 rootfs.img创建挂载镜像文件的目录,挂载之后写入,然而我在这一步遇到了阻碍,提示没权限。网上教程可能不会遇到这个问题,但是其实用docker久了就知道很可能是privileged没开的问题,当然,在上面的命令里我已经补充好了。对于mount之类的命令,即使docker内部是root,但是在外部没有权限,也是会报权限问题的,我对这里并没有细究,加上之后没问题就放过了。挂载好之后,把busybox直接编译到挂载目录下mkdir fs mount -t ext4 -o loop rootfs.img ./fs > mount: ./fs: mount failed: Operation not permitted. # docker创建容器的命令加上 --privileged=true解决 make install CONFIG_PREFIX=./fs cd fs mkdir proc dev etc home mnt cp -r ../examples/bootfloppy/etc/* etc/ chmod -R 777 ./ 2.4 运行Linux内核qemu-system-x86_64 -kernel /root/source/linux-6.4/arch/x86/boot/bzImage -hda /root/tools/busybox-1.36.1/rootfs.img \ -append "root=/dev/sda console=ttyS0" -nographic可以看到成功运行之, Ctrl-A 后按X退出qemu
-
Linux Kernel-Zswap 2.上下层依赖 上下层依赖重要数据结构zswap_poolstruct zswap_pool { // 挂 zswap 所用的内存池 struct zpool *zpool; struct crypto_acomp_ctx __percpu *acomp_ctx; struct kref kref; struct list_head list; struct work_struct release_work; struct work_struct shrink_work; struct hlist_node node; char tfm_name[CRYPTO_MAX_ALG_NAME]; };struct zpool *zpool:指向 zpool 对象的指针,用于表示当前 zswap 池所对应的 zpool。可能需要基于 uma 进一步封装实现。struct crypto_acomp_ctx __percpu *acomp_ctx:指向压缩算法。struct crypto_acomp_ctx { struct crypto_acomp *acomp; struct acomp_req *req; struct crypto_wait wait; u8 *dstmem; struct mutex *mutex; };struct kref kref:用于实现引用计数技术的 kref 对象,用于管理 zswap 池对象的生命周期。当一个 zswap 池对象被创建时,其引用计数值初始化为 1;当该对象被使用时,其引用计数值增加;当不再需要该对象时,其引用计数值减少,当引用计数值降为 0 时,该对象将会被释放。 FreeBSD 支持 refcount 特性,我们认为是可以迁移的。struct list_head list:用于实现链表的 list_head 结构体,用于将当前 zswap 池对象添加到 zswap 的池列表中。普通链表头,可以迁移。struct work_struct release_work:表示一个工作队列对象,用于异步释放当前 zswap 池对象。在该工作队列中执行的操作会在一个单独的内核线程上运行,从而避免阻塞当前进程。struct work_struct shrink_work:表示一个工作队列对象,用于在 zswap 池中的页面数量超过一定阈值时触发缩减操作。该工作队列也是异步执行的,在单独的内核线程上运行。FreeBSD 的 taskqueue 和 workqueue类似,都支持异步调用,可以迁移。struct hlist_node node:表示一个哈希表节点,用于将当前 zswap 池对象添加到 zswap 的池哈希表中。char tfm_name[CRYPTO_MAX_ALG_NAME]:表示保存压缩算法名称的字符数组,用于指定 zswap 池所使用的压缩算法名称。在进行前端交换时,内核将会根据该名称来查找相应的压缩算法,并使用其进行数据压缩处理。zswap_entrystruct zswap_entry { struct rb_node rbnode; pgoff_t offset; int refcount; unsigned int length; struct zswap_pool *pool; union { unsigned long handle; unsigned long value; }; struct obj_cgroup *objcg; };struct zswap_entry 表示单个被压缩页面元数据。struct rb_node rbnode:红黑树节点pgoff_t offset:表示该页面在交换分区中的偏移量,也是红黑树的 idxint refcount:表示对该页面的引用计数,用于保证在页面同时被加载、失效和写回等操作时不会出现条件竞争,从而避免页面被过早地释放。unsigned int length:被压缩后页面长度。struct zswap_pool *pool:标识该页面所属的 zswap 池。union:a) unsigned long handle:压缩页面数据句柄。这个是 zpool 用的。b) unsigned long value:内容相同的空白页面填充值。struct obj_cgroup *objcg:指向 obj_cgroup 结构体的指针,用于标识该页面所属的 cgroup(如果按 cgroup 进行回收)。zswap_treestruct zswap_tree { struct rb_root rbroot; spinlock_t lock; };这个结构体代表了一个 zswap 树的元信息,分别有一个红黑树的根和一个自旋锁。一点对 zswap_pool\entry\tree的理解enrty 是页面单元,包括该页在内存中的位置大小等信息,pool是实际存储 entry 元信息对应页面压缩后数据的内存池,tree 维护了一颗平衡树,用于找到对应 type+offset 的元信息entry。zswap_header一个 ulong其他全局变量一般为 config 或者全局状态量,易于迁移。page篇幅过长,Linux 的基础页面数据结构重要依赖模块内存管理池 zpoolzpool 是 linux 的一类内存管理 API,是 zswap 所依赖的最底层的数据结构。zswap_pool 通过 zpool 的各类内存管理工具,包括申请、映射、收缩等关键操作异步压缩 acompressacompress 是 linux crypto 下的模块,它提供了类似队列式的异步的压缩和解压缩能力同时,crypto 模块还提供了统一的同步方式swap 框架 frontswap提供了一种 swap 接口层,通过实现 frontswap 提供的函数指针,可以自定义swap 的实现方式有了 frontswap,我们只需要关注 swap 后端的设计,并向对应的初始化、存入、取出等接口实现逻辑、提供功能即可。frontswap 是zswap 最重要的依赖之一平衡树 rbtree维护 zswap_tree 的核心数据结构,保证插入和索引 offset 对应的页面的时候的复杂度。工作队列work_queue提供一个异步工作的机制,包括对 pool 的 shrink 和 release引用计数 kref需要一个引用计数器,主要是保证在 pool 和 entry被释放时的内存安全性锁与信号量主要需要关于自旋锁和互斥锁的 aquire/release的实现,避免线程竞争带来的各类安全和数据访问问题。原子操作一般依赖模块认为一般依赖模块仅是为了某些特性准备,不影响 swap 的关键流程scatterlist为了支持 acomp 的参数而依赖,属于间接依赖多 CPU 系列的宏和回调注册有的为了支持 CPU 热插拔事件、有的为了实现 acomp 在多 CPU 上的真并行kmem_cacheentry_cache 的底层申请与管理依赖于 kmem_cache,属于性能优化。
![Linux Kernel-THP阅读分析[Hang up]](https://yirannn.com/usr/themes/Joe/assets/thumb/23.jpg)


