搜索到
14
篇与
的结果
-
 sec19-ERIM: Secure, Efficient In-process Isolation with Protection Keys (MPK) Insight面对在共享内存中隔离进程关键数据的需求,ERIM提供了一个利用Intel MPK机制来近乎零开销的隔离组件的机制。使用MPK比现有SoTA开销低3-13倍,但是MPK本身不安全,因为写PKRU寄存器是无权限控制的。ERIM提供了一个保护安全性的机制。Background这里要介绍一下MPK,MPK提供了16个保护键,每个页面都可以与其中一个关联。提供了一个每个核心独立的寄存器PKRU,PKRU决定了当前核心在每个域的访问权限。并且这种权限检查是无开销的。PKRU使用用户态命令WROKRU和XRSTOR两条指令,但是这两条指令本身并没有被很好的保护起来,ERIM提出的机制正是为了保护指令避免被恶意攻击使用。DesignERIM的前提是系统的一些基础保护,如NX、DEP等保护已经开启,并且可以访问核心区的代码必须是完全可信的。design principleERIM通过限定WRPKRU和XRSTOR的出现条件实现对指令的保护,其要求相关指令在执行后必须进入预定几个几个流程之一对于WRPKRU,要么进入预定的入口点,这样即使权限错误,也只会进入到可信的代码后续操作未访问隔离内存,并且会结束进程对于XRSTOR后续指令必须是一段检查eax寄存器的代码,因为如果eax没有被控制,PKRU不会被错误的设定call gateERIM为可信代码设计了预定的入口点,在入口点调整PKRU,并将控制流转交可信代码,在可信代码完成之后,再调整PKRU。调用门有所限制。binary inspection二进制扫描包含WRPKRU字节序列的页面是否安全,这需要提前获得指定的入口点列表。通过二进制扫描来确保是否符合给定条件。
sec19-ERIM: Secure, Efficient In-process Isolation with Protection Keys (MPK) Insight面对在共享内存中隔离进程关键数据的需求,ERIM提供了一个利用Intel MPK机制来近乎零开销的隔离组件的机制。使用MPK比现有SoTA开销低3-13倍,但是MPK本身不安全,因为写PKRU寄存器是无权限控制的。ERIM提供了一个保护安全性的机制。Background这里要介绍一下MPK,MPK提供了16个保护键,每个页面都可以与其中一个关联。提供了一个每个核心独立的寄存器PKRU,PKRU决定了当前核心在每个域的访问权限。并且这种权限检查是无开销的。PKRU使用用户态命令WROKRU和XRSTOR两条指令,但是这两条指令本身并没有被很好的保护起来,ERIM提出的机制正是为了保护指令避免被恶意攻击使用。DesignERIM的前提是系统的一些基础保护,如NX、DEP等保护已经开启,并且可以访问核心区的代码必须是完全可信的。design principleERIM通过限定WRPKRU和XRSTOR的出现条件实现对指令的保护,其要求相关指令在执行后必须进入预定几个几个流程之一对于WRPKRU,要么进入预定的入口点,这样即使权限错误,也只会进入到可信的代码后续操作未访问隔离内存,并且会结束进程对于XRSTOR后续指令必须是一段检查eax寄存器的代码,因为如果eax没有被控制,PKRU不会被错误的设定call gateERIM为可信代码设计了预定的入口点,在入口点调整PKRU,并将控制流转交可信代码,在可信代码完成之后,再调整PKRU。调用门有所限制。binary inspection二进制扫描包含WRPKRU字节序列的页面是否安全,这需要提前获得指定的入口点列表。通过二进制扫描来确保是否符合给定条件。 -
OSDI14- Arrakis: The Operating System is the Control Plane Wordsmediate v. 调节,斡旋negligible adj. 微不足道的Insight传统服务器通过内核协调进程隔离和网络、磁盘等IO设备的安全性,本文实现了一个操作系统,允许应用程序IO跳过内核。也就是所谓的控制平面和数据平面分离。Achievement一个典型NoSQL场景下的存储延迟优化了2-5倍,吞吐量提高了9倍提出了一种分工架构,并实现了一个原型操作系统,在此基础上测量了一部分现实服务的性能Breakdown Analysis从网络开始,传统Linux接受一个网络包的时间在微秒级别,通常是3us、6us两个时间级别,差别在于收包进程是否在idle,并且相差的开销以schedule带来的开销为主。而在3us中,主要的时间都浪费在了网络栈上。主要的开销集中于以下四点网络栈开销调度器开销内核切换开销数据包复制开销除此之外,多核导致的缓存和锁也会增加开销Arrakis可以完全消除调度器和内核切换的开销,并且极大的消除了网络栈和数据包复制的影响。同时文章分析了在存储侧系统调用带来的影响,以1KB为例,ext4的CPU开销大概要在30us级别,btrfs在70us级别,而RAID缓存的写延迟大概25us,闪存低至15us,这意味着文件系统带来的开销甚至要比硬件写入的开销更大。后续的阅读中我可能没再关注网络侧的内容,主要关注Storage,以及他们提出的这种硬件模型所提供的能力及用途。Design&Imp文章描述了一个基于一类特定的(主要是硬件级别支持虚拟化的)IO设备的架构。现有设备和控制器只能在某些方面实现他们提出的这种硬件模型。访问层级主要分为App、LibOS、VSIC、VSA和Device。App通过定制的UserSpace Lib来访问VSIC,即虚拟存储界面控制器,同时,硬件设备需要将物理段映射为多个虚拟存储区域VSA,VSA和VSIC是一个多对多的映射关系,VSIC由App创建。App通过API可以通过VSIC中的命令队列读取、写入VSA中任意偏移和大小的磁盘,完成使用doorbell通知。整个用户访问文件的流程不需要操作系统介入。那么问题就到了文件是如何共享和访问控制的。Arrakis分离了文件的命名和实现。App可以任意的通过VSA存储metadata和文件等内容。并可以将文件、目录名导出到vfs中,仍由原App管理,外部的访问不会被内核干预。外部访问可以通过RPC把原APP当做一个Server访问,或者源程序提供一个可以独立运行的进程。VSA也可以映射到多个进程中,此时访问APP需要能读到原APP的metadata,并能有适当的库解析文件内容。访问控制控制整个VSA是否可见。用户可以直接导出文件为标准格式。我感觉这三个方案都有点过于牵强了。
-
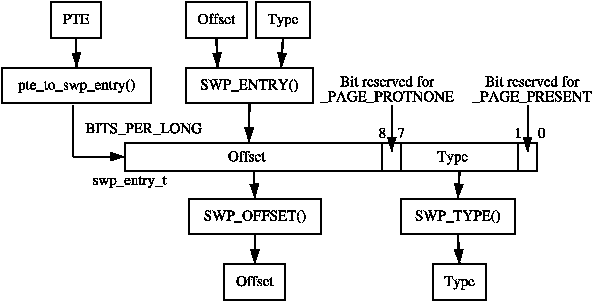
Zswap4BSD接入 BSD Swap 这一步是比较艰巨的,上一篇文章里虽然看上去都是fanyi的锅,实际上问题是我都是处理一些迁移好的依赖(by linuxkpi),而fanyi需要弄一个没有的依赖(没有那么好接,需要读一下源码)到了我们这,Linux和FreeBSD的swap区别还是蛮大,我将会首先梳理Linux中是如何在swap之前先调用frontswap的,再梳理FreeBSD的swap到底是怎么运转的,最后再选择一种合理的方式(尽量照抄Linux)把frontswap接入到 BSD 中。Frontswap的一探究竟Frontswap作为一个中间层,为优化方式提供了一种接口,使得页面在真正换出到swap设备之前可以先进入frontswap,如果frontswap成功,则不必再换出。从下层接口看起struct frontswap_ops { void (*init)(unsigned); /* this swap type was just swapon'ed */ int (*store)(unsigned, pgoff_t, struct page *); /* store a page */ int (*load)(unsigned, pgoff_t, struct page *); /* load a page */ void (*invalidate_page)(unsigned, pgoff_t); /* page no longer needed */ void (*invalidate_area)(unsigned); /* swap type just swapoff'ed */ };这里没加参数名字,但是那个unsigned都是type, pgoff_t 都是offset就好了。现在frontswap只有一个driver,即zswap,所以我们都会结合zswap来说。在我理解,一个type对应的是一个swap设备,或者说,我们每次做swapon系统调用的时候,那个对应的文件就是一个设备,当成一个逻辑设备就好了(毕竟万物皆文件嘛)。在这种基础上,我们就很好理解了,frontswap要求driver可以区分不同的设备,根据不同的设备初始化、插入、加载和删除页面。以及可以失效一整个设备的所有页面。上层接口extern void frontswap_init(unsigned type, unsigned long *map); extern int __frontswap_store(struct page *page); extern int __frontswap_load(struct page *page); extern void __frontswap_invalidate_page(unsigned, pgoff_t); extern void __frontswap_invalidate_area(unsigned);相对应的,frontswap也为上层提供了一系列接口,其中参数大差不差,store和load会提取page中的private字段,最后拆成type和offset,再塞给下层,这可能是我们要在过程中关注的一点,一个页面在什么时候会获得这个private,它是怎么跟pid和虚拟内存的offset对应上的?我们在FreeBSD里如何把swap的vm_object和offset 跟这个private对应起来?我们好像没有那么多地方能存放数据。总不能把zswap改成二重索引的树套树。除此之外,frontswap还在对应swap设备的控制结构swap_info_struct中留下了一个unsigned long *类型的参数map,用于中间层校验当前的page是否在frontswap中存在,及相应的是否有效上层接口到下层接口1. Driver的注册在做zswap的时候我们已经很明显的看到了,frontswap用register函数注册相关的控制结构int frontswap_register_ops(const struct frontswap_ops *ops) { if (frontswap_ops) return -EINVAL; frontswap_ops = ops; static_branch_inc(&frontswap_enabled_key); return 0; }注册的过程伴随着swap设备的swapon,但是存在一种情况即backend driver还没准备好,我们就要往里写了,所以frontswap的每个操作都会在操作前首先检测注册情况2. initvoid frontswap_init(unsigned type, unsigned long *map) { struct swap_info_struct *sis = swap_info[type]; VM_BUG_ON(sis == NULL); if (WARN_ON(!map)) return; frontswap_map_set(sis, map); if (!frontswap_enabled()) return; frontswap_ops->init(type); }这个map是个bitmap,用来判断一个页面是不是在frontswap里,初始化的时候,要新建一个map赋给这个设备的swap_info3. test & set & clear听起来就像bit操作,实际上也确实是,这两个函数根据给定的swap_info和offset,把map的第offset位返回/置1/清除4. store & load终于到了比较核心的地方int __frontswap_store(struct page *page) { int ret = -1; swp_entry_t entry = { .val = page_private(page), }; int type = swp_type(entry); struct swap_info_struct *sis = swap_info[type]; pgoff_t offset = swp_offset(entry); if (__frontswap_test(sis, offset)) { __frontswap_clear(sis, offset); frontswap_ops->invalidate_page(type, offset); } ret = frontswap_ops->store(type, offset, page); if (ret == 0) { __frontswap_set(sis, offset); inc_frontswap_succ_stores(); } else { inc_frontswap_failed_stores(); } return ret; } 就和我们之前说的一样,首先从private中拆出来private字段,拆成type和offset,验证当前页面是否在frontswap中已经出现了,如果出现,首先干掉,然后再把页面塞进去int __frontswap_load(struct page *page) { int ret = -1; swp_entry_t entry = { .val = page_private(page), }; int type = swp_type(entry); struct swap_info_struct *sis = swap_info[type]; pgoff_t offset = swp_offset(entry); if (!__frontswap_test(sis, offset)) return -1; ret = frontswap_ops->load(type, offset, page); if (ret == 0) inc_frontswap_loads(); return ret; }load也差不多,这边如果检测到不在,那就直接返回失败,否则load一下。至于后面的两个invalid,我们等到他们被调用的时候再看好了。那它在哪被调用呢?别急,我们先去看看Linux的Swap吧Linux Swap的浅述swap应该是大家都听过的概念,废话不多说,不管是linux还是unix,只有匿名页面在需要内存回收的时候,需要放在swap分区中,以便重新访问的时候调入内存,不然只能OOM Kill了,而以文件做backend的页面可能是不需要换出的(可读写页面可能会分情况,比如出现了CoW之后再设置为可以换出的页面)什么时候发生swap?周期性检查,保证内存有充足空间:mm/vmscan.c - kswapd()直接内存回收,当内存不够用的时候: mm/page_alloc.c - __alloc_pages_slowpath我们关心的第一个问题:swp_entry_t 从哪里来,又到哪里去来看一张图swp_entry就是一个long,和一个PTE等长,正好可以放进一个页表作为一个页表项,当swap out的时候,linux在回收物理页面之前先修改这个PTE,这样下次访问到这个PTE的时候就会触发一个Page Fault,再通过这个swp_entry_t找到原来这个页面在swap中的位置,进而换出,再把这个表项修改成真的PTE。PTE的如下三种情况全为0:该页不属于进程的地址空间,或相应的页框尚未分配给进程。最低位为0,其余位不全为0:该页现在在swap分区中。最低位为1:present位为1,表示该页在内存中。直接转换。至于FreeBSD怎么办,我们一会再想,反正现在是知道这个entry是咋来的了swap是怎么调用frontswap的?失败了怎么办?什么时候initSYSCALL_DEFINE2(swapon, const char __user *, specialfile, int, swap_flags) { // ... if (IS_ENABLED(CONFIG_FRONTSWAP)) frontswap_map = kvcalloc(BITS_TO_LONGS(maxpages), sizeof(long), GFP_KERNEL); // ... enable_swap_info(p, prio, swap_map, cluster_info, frontswap_map); // ... } static void enable_swap_info(struct swap_info_struct *p, int prio, unsigned char *swap_map, struct swap_cluster_info *cluster_info, unsigned long *frontswap_map) { if (IS_ENABLED(CONFIG_FRONTSWAP)) frontswap_init(p->type, frontswap_map); }swapon的时候,这个调用链路实在太明确啦,就不说了,因此我们大概也是要找到FreeBSD对应的Swapon,幸运的是,这个应该不是很难。什么时候Store肯定是先Store再load啦,我们先看Store好了。在mm/page_io.c下int swap_writepage(struct page *page, struct writeback_control *wbc) { // some other code if (frontswap_store(&folio->page) == 0) { folio_start_writeback(folio); folio_unlock(folio); folio_end_writeback(folio); return 0; } __swap_writepage(&folio->page, wbc); return 0; }如果走frontswap成功,就不走后面的write_page了,调用start_writeback,然后结束流程。然而这块很显然出现了一个问题,folio_xx_writeback是用来干啥的呢?按理说,我们是在swap之前就把该unmap的已经unmap掉了,最核心的写入部分也搞完了,应该只能有点收尾工作,不能有writeback啊?这个问题稍后再看,我们把frontswap看完什么时候load读取的部分是+号位有点长void swap_readpage(struct page *page, bool synchronous, struct swap_iocb **plug) { struct swap_info_struct *sis = page_swap_info(page); bool workingset = PageWorkingset(page); unsigned long pflags; bool in_thrashing; VM_BUG_ON_PAGE(!PageSwapCache(page) && !synchronous, page); VM_BUG_ON_PAGE(!PageLocked(page), page); VM_BUG_ON_PAGE(PageUptodate(page), page); /* * Count submission time as memory stall and delay. When the device * is congested, or the submitting cgroup IO-throttled, submission * can be a significant part of overall IO time. */ if (workingset) { delayacct_thrashing_start(&in_thrashing); psi_memstall_enter(&pflags); } delayacct_swapin_start(); if (frontswap_load(page) == 0) { SetPageUptodate(page); unlock_page(page); } else if (data_race(sis->flags & SWP_FS_OPS)) { swap_readpage_fs(page, plug); } else if (synchronous || (sis->flags & SWP_SYNCHRONOUS_IO)) { swap_readpage_bdev_sync(page, sis); } else { swap_readpage_bdev_async(page, sis); } if (workingset) { delayacct_thrashing_end(&in_thrashing); psi_memstall_leave(&pflags); } delayacct_swapin_end(); }别看这里多了几个if else,其实store只是把这几个if-else包了一层,如果失败自动回归原流程,好像也没啥需要特别注意的。至于range_free(invalidate)什么的,我们倒是不着急,先把核心做出来吧.
-
FreeBSD Arch Handbook阅读笔记 #7 VM https://docs.freebsd.org/en/books/arch-handbook/vm/7.1 vm_page_tvm_page_t 管理物理内存,每个vm_page_t对应一个物理页面,vm_page_t属于不同双向链表队列。主要包括活动、非活动、缓存或空闲。缓存和空闲的分页队列更加复杂,会根据L1和L2 Cache的大小分成多个队列。申请新页面的时候也会从Cache的角度来申请对齐的页面。页面通过引用计数持有,通过繁忙计数锁定。VM system通过LRU来对页面进行降级。对于Weird类型的页面,不在队列里,通常是载有一个页表。空闲链表里的页面是真正空闲的,而Cache链表里的页面随时可被重用。当进程访问一个不在页表里的页面时,如果页面在页面队列里,页错误就会导致更少的开销。否则只能从外存读入了。pageout守护进程负责:动态调整分页队列、维持各个队列页面合理比例维持脏页面和干净页面的细分(清洗脏页、升降级)VM会尝试在产生合理的页错误量级的前提下帮助决策何时换出和清洗页面。7.2 vm_object_tFreeBSD实现了一个通用内存对象,这个对象的backend可以是:TypesunbackedSwap-backedPhysical device backedFile-backedVM对象可以被遮蔽,具体可以看我的另一篇笔记https://yirannn.com/source_code/vm_sys.html比较常见的应用就是cow一个vm_page_t同时只能和一个vm_object关联。而不同实例的内存共享由遮蔽特性提供7.3 struct buf对于vnode作为back的vm对象,比如file,对脏页信息的维护和vm对脏页信息的维护是相互独立的。在写回脏页时,vm需要在写回前清除dirty标记。另外文件也需要将文件映射到KVM才能进行操作,这种结构被称为文件系统缓冲区,一般是struct buf,文件系统需要对VM进行操作时,把这个vm对象转换为一个buf,然后把buf中的页面映射在KVM里。同理,磁盘IO也是先把vm_object映射到buf,再在buf上发出IO。7.4 vm_map_t, vm_entry_tFreeBSD通过vm_map_t结构把object和虚拟内存范围相关联,页表通过vm_map_t/vm_entry_t/vm_object_t 直接合成。这一段我其实没太读懂,但是我感觉笔者意思是一个物理页不光是和一个vm_object联系,同时也和页表项联系。但是对于同个object的同个页面,对应的vm_page_t都相同7.5 KVM 内存映射FreeBSD用KVM保存内核结构,其中最大的就是7.3中提到的buf。FreeBSD不会把所有物理内存都映射到KVM,主要利用区域分配器管理KVM
-
部署一个基于VMWare的FreeBSD工作环境 概述在开发FreeBSD Kernel的过程中,发现基于Linux交叉编译的方法实在是过于不便,大量FreeBSD的脚本都是为了BSD自己准备的,因此搭建一个FreeBSD的开发环境,以便未来减少阻力。该环境至少应该能支持:基础的代码浏览与修改功能基础的代码提示、补全与Linter完备的编译环境测试编译产生的内核的虚拟机在这里,编译环境应该是相对好解决的,我们需要自己找到代码提示补全和虚拟机的方案。FreeBSD直接下载Index of /releases/VM-IMAGES/13.2-RELEASE/amd64/Latest/,然后新建虚拟机加载即可如果用vmware,安个tools先pkg install open-vm-toolsGUI换个源先FreeBSD pkg 源使用帮助 ‒ USTC Mirror Help 文档qcow出现的问题vmdk也一样,需要给虚拟磁盘扩容下先https://developer.aliyun.com/article/758140?spm=a2c6h.12873581.0.0.34342784yoZBWHpkg install xorg xfce startxfce4共享文件夹挂载很坑,这里只提供vmware的在 /boot/loader.conf加入fusefs_load="YES"在 /etc/fstab加入.host:/ /root/mnt/hgfs fusefs rw,mountprog=/usr/local/bin/vmhgfs-fuse 0 0安装toolspkg install open-vm-tools mkdir -p /mnt/hgfs rebootreboot之后可以执行kldstat这里应该有个fusefs.ko就对了此时可以看看/mnt/hgfs下有没有内容了(当然前提是Vmware里配了)到此为止,可以通过共享文件夹的方式进行编译了(但是灰常慢)为FreeBSD配置SSH修改/etc/inetd.conf,把ssh tcp前面的注释干掉修改/etc/rc.conf 加入 sshd_enable="YES"修改/etc/ssh/sshd_config把 PasswordAuthentication 的 no改为yes,注释去掉,允许PAM登录【可选的,我没开其实】把 PermitRootLogin no 改为 yes,注释去掉【可选的,我不是生产环境,用root方便】把 PubkeyAuthentication 注释去掉,允许通过key登录,然后自己配个authorized_keys查看虚拟机ip:用passwd改个密码此时就可以ssh上来啦配置sudo安装个sudo、创建个用户pkg install sudo adduser添加到wheel组,为了可以su到rootpw group mod wheel -m yyi设置sudoersvisudo这行注释去掉测试一下即可配置zsh+ohmyzsh我的这些shell基本上都是一样的ohmyzsh+powerlevel10k,不赘述了配置vscode-remote[失败了]Vscode 的 ssh-remote不支持freebsd,但是配置一下并不难启用一下freebsd的linux兼容模式sudo sysrc linux_enable="YES" sudo service linux start sudo pkg install linux_base-c7vscode-remote最后也没成功,因为remote一定要在ssh后面加个命令(即使我在config中已经制定了remote命令)还是选择git同步吧。最后记得打个快照